Optimize SQL Server อย่างไรให้เร็วขึ้น 900 เท่า
แอพทุกชนิดมักจำเป็นต้องเรียกหาสืบค้นข้อมูลจากฐานข้อมูล SQL ด้วยการเขียน Query ไม่ว่าแอพจะดีแค่ไหน แต่ถ้าQueryไม่มีประสิทธิภาพ แอพก็จะทำงานช้าเพราะต้องรอข้อมูล ในบทความนี้ 9Expert จะเสนอวิธีปรับปรุงประสิทธิภาพการทำงานของ Query เพื่อให้แอพทำงานได้รวดเร็วราบรื่นขึ้น โดยแสดงตัวอย่างการทำงานใน Microsoft SQL Server Express Edition ที่ไมโครซอฟท์เปิดให้ดาวน์โหลดและใช้งานได้ฟรี ส่วนผู้ที่ใช้ SQL Server edition อื่น เช่น Enterprise, Standard, web หรือ developer edition ก็สามารถปฏิบัติตามแบบฝึกหัดได้
ส่วนเครื่องมือสำหรับป้อนพิมพ์สคริปต์จะใช้โปรแกรม SQL Server Management Studio (SSMS) community เวอร์ชัน 21 ที่ไมโครซอฟท์เปิดให้ดาวน์โหลดและใช้ได้ฟรีเช่นกัน
ฐานข้อมูลตัวอย่างสำหรับการทดสอบ
Query ทั้งหมดในบทความนี้จะทำงานกับฐานข้อมูล LoyDB2025 ที่ท่านสามารถดาวน์โหลดได้จาก: https://github.com/laploy/test1/blob/main/LoyDB2025.zip
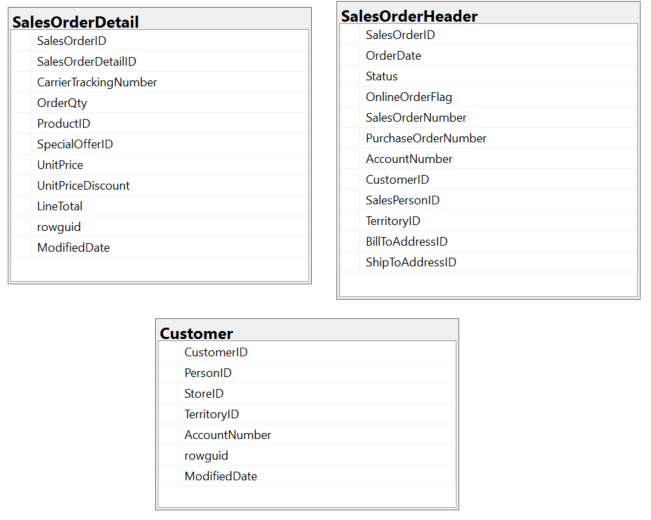
ฐานข้อมูลนี้ประกอบด้วย 3 ตาราง ได้แก่
- SalesOrderDetail: (รายละเอียดใบสั่งขาย): ตารางนี้เก็บข้อมูลรายละเอียดของแต่ละรายการในใบสั่งขาย เช่น รหัสใบสั่งขาย (SalesOrderID), รหัสรายละเอียดใบสั่งขาย (SalesOrderDetailID) และคอลัมน์อื่น ๆ
- SalesOrderHeader: (ส่วนหัวใบสั่งขาย): ตารางนี้เก็บข้อมูลภาพรวมของใบสั่งขายแต่ละใบ เช่น รหัสใบสั่งขาย (SalesOrderID), วันที่สั่งซื้อ (OrderDate), สถานะ (Status), และคอลัมน์อื่น ๆ
- Customer: (ลูกค้า): ตารางนี้เก็บข้อมูลเกี่ยวกับลูกค้า เช่น รหัสลูกค้า (CustomerID), รหัสบุคคล (PersonID), รหัสร้านค้า (StoreID) และคอลัมน์อื่น ๆ
ฐานข้อมูลนี้ออกแบบมาเพื่อจัดการข้อมูลเกี่ยวกับการสั่งซื้อสินค้าและข้อมูลลูกค้า ซึ่งเป็นโครงสร้างทั่วไปที่ใช้ในระบบการจัดการคำสั่งซื้อ (Order Management System) หรือระบบการวางแผนทรัพยากรองค์กร (ERP) ในส่วนที่เกี่ยวกับการขาย
แต่ละตารางมีข้อมูลตัวอย่างประมาณสองหมื่นถึงหนึ่งแสนแถว ไม่มีการเชื่อมโยงระหว่างตาราง แต่ละตารางไม่ไฟล์ดรรชนี และไม่มีไฟล์วิวใด ๆ ทั้งสิ้น
วิธีติดตั้งฐานข้อมูล
- เมื่อดาวน์โหลดเสร็จแล้วให้คลายการบีบไฟล์ จะได้ไฟล์ชื่อ LoyDB2025.bak
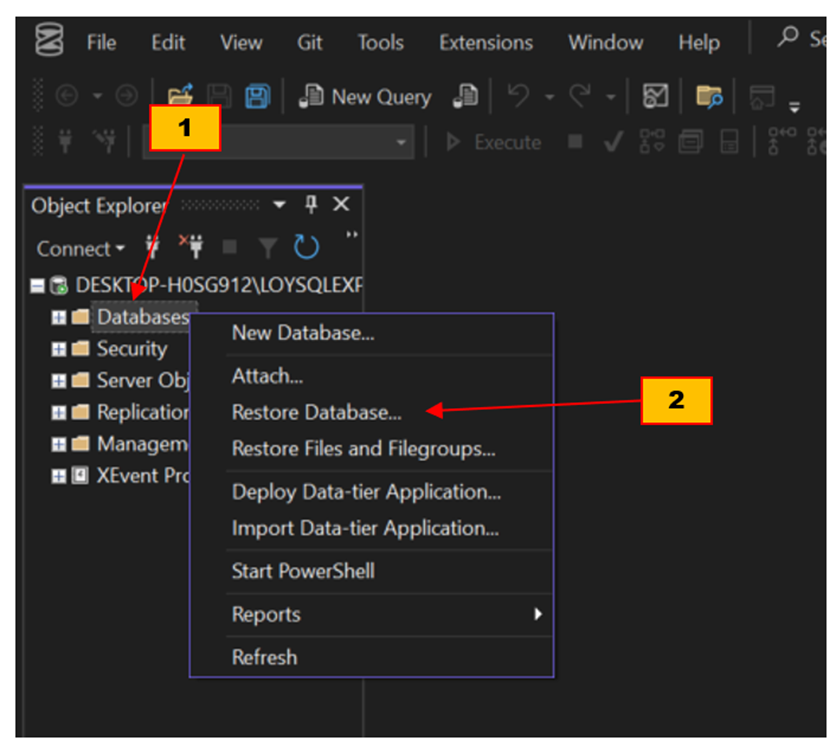
- เปิดโปรแกรม SSMS คลิกขวาที่หัวข้อ Database ใน Object Explorer (1) แล้วคลิกที่หัวข้อ Restore Database จาก context menu (2) เพื่อเปิดกรอบข้อความ Restore Database
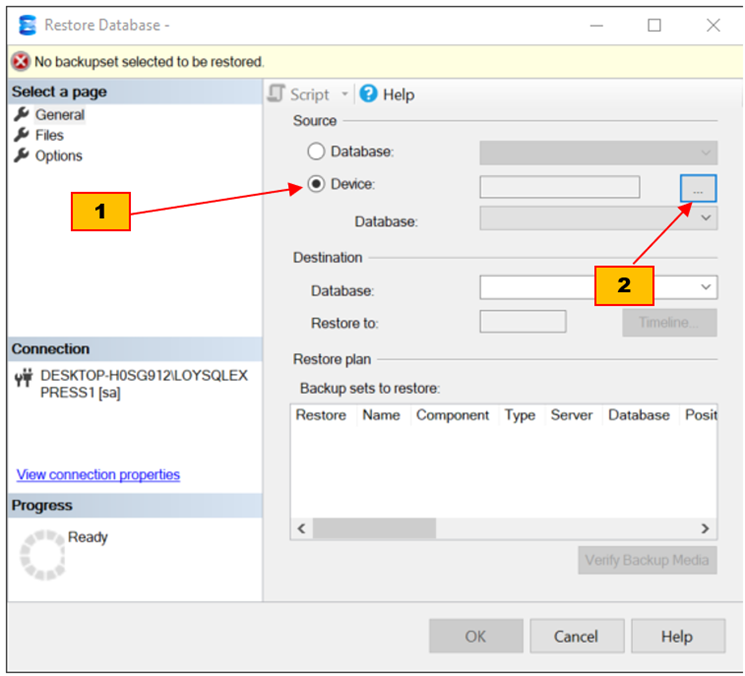
- กดที่ radio button device (1) กดที่ปุ่ม select backup device (2) เพื่อเปิดกรอบข้อความ Select Backup Device
- ในกรอบข้อความ Select Backup Device กดปุ่ม Add เพื่อเปิดกรอบข้อความ Locate backup file
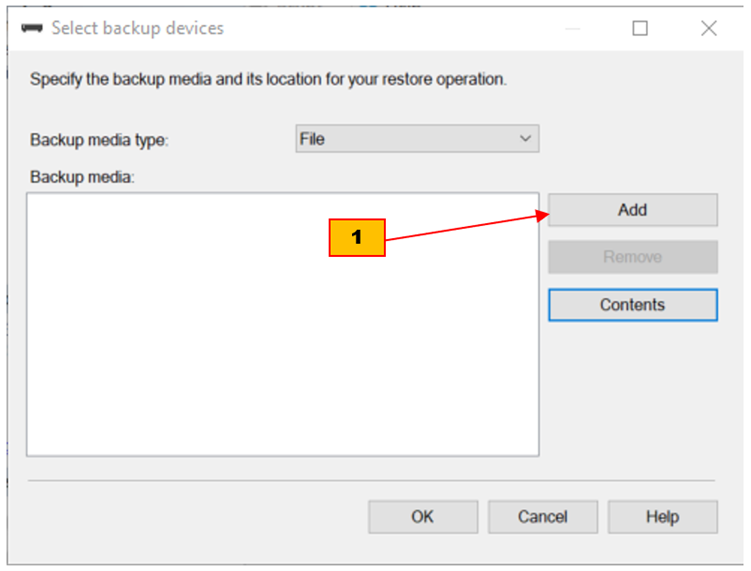
- ในกรอบข้อความ Locate backup file ให้หาและกดที่ไฟล์ LoyDB2025.bak
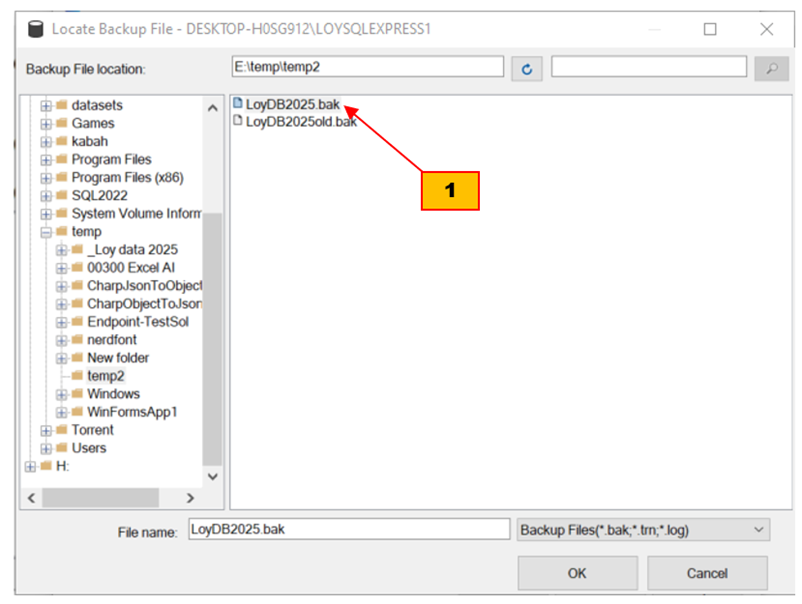
- ทำขั้นตอนที่เหลือให้ครบโดยกดปุ่ม OK ในหน้านี้และในกรอบข้อความ Select Backup Device ก่อนหน้านี้
ดาวน์โหลด Query
สคริปต์ SQL ทั้งหมดในบทความนี้เป็นภาษา T-SQL (Transact-SQL ภาษาสคริปต์สำหรับใช้กับโปรแกรม Microsoft SQL Server) ท่านสามารถป้อนพิมพ์โค้ดตามตัวอย่างได้ สำหรับผู้ที่ไม่ต้องการป้อนพิมพ์โค้ดเอง สามารถดาวน์โหลดสคริปต์ทั้งหมดได้จาก:
https://github.com/laploy/test1/blob/main/LoyOpt.zip
ภายในไฟล์ zip ท่านจะพบไฟล์สคริปต์ต่าง ๆ ที่ท่านสามาราถนำมารันได้โดยตรง ดังนี้
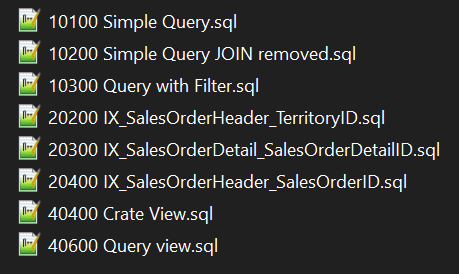
หน้าที่ของแต่ละสคริปต์โดยย่อ
- 10100 Simple Query.sql: Queryแรก ดึงข้อมูลจากสามตาราง
- 10200 Simple Query JOIN removed.sql: Queryแบบตัดจอยออก
- 10300 Query with Filter.sql; Queryที่เพิ่มคำสั่ง WHERE
- 20200 IX_SalesOrderHeader_TerritoryID.sql: Queryสร้างดรรชนีที่ 1
- 20300 IX_SalesOrderDetail_SalesOrderDetailID.sql: Queryสร้างดรรชนีที่ 2
- 20400 IX_SalesOrderHeader_SalesOrderID.sql: Queryสร้างดรรชนีที่ 3
- 40400 Crate View.sql: Queryสร้างวิวและดรรชนีของวิว
- 40600 Query view.sql: Queryดึงข้อมูลจากวิว
เริ่มจาก Query พื้นฐานสุด
นี่คือคำสั่งทำหน้าที่ดึงข้อมูลลูกค้าและคำสั่งซื้อจากฐานข้อมูล LoyDB2025
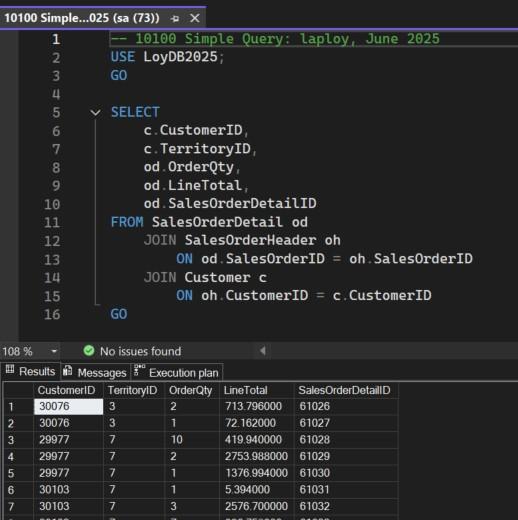
สคริปต์ 10100 Simple Query.sql
คำอธิบายแต่ละส่วนของสคริปต์
- บรรทัดที่ 2: กำหนดให้ฐานข้อมูลที่ใช้งานในปัจจุบันเป็น LoyDB2025
- บรรทัดที่ 5-15: ดึงข้อมูลจาก 3 ตาราง ใช้คำสั่ง JOIN โดยไม่ระบุวิธีจอย SQL Server จะถือว่าเป็น INNER JOIN ที่จะรวมข้อมูลเฉพาะแถวที่มีค่าตรงกันในแต่ละตาราง
ตารางและความสัมพันธ์
- SalesOrderDetail (od): เก็บรายละเอียดรายการสินค้าในคำสั่งซื้อแต่ละรายการ
- SalesOrderHeader (oh): เก็บข้อมูลสรุปของคำสั่งซื้อ เช่น รหัสลูกค้า
- Customer (c): เก็บข้อมูลของลูกค้า
การจอยตาราง (JOIN)
- จอยตาราง SalesOrderDetail กับตาราง SalesOrderHeader ผ่านคอลัมน์ SalesOrderID เพื่อให้รู้ว่าแต่ละรายการคำสั่งซื้ออยู่ในคำสั่งซื้อใด
- จอยตาราง SalesOrderHeader กับตาราง Customer ผ่านคอลัมน์ CustomerID เพื่อให้รู้ว่าแต่ละคำสั่งซื้อเป็นของลูกค้ารายใด
คอลัมน์ที่ดึง
- CustomerID, TerritoryID จากตาราง Customer
- OrderQty, LineTotal, SalesOrderDetailID จากตาราง SalesOrderDetail
- SalesOrderID จากตาราง SalesOrderHeader
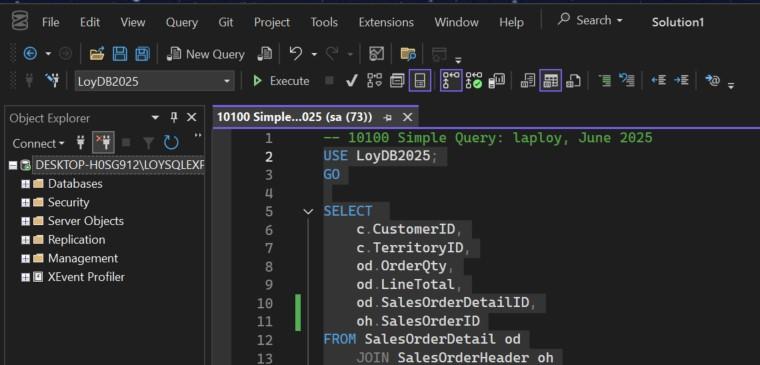
วิธีรันสคริปต์
- กดปุ่ม Include Actual Execution Plan (2) ครั้งแรกครั้งเดียว เพื่อกำหนดให้ฟังก์ชันนี้ทำงาน
- กดปุ่ม Execute เพื่อรันสคริปต์ (1)
วิธีอ่านแผนดำเนินการ (Execution Plan)
ก่อนจะปรับปรุงประสิทธิภาพของQueryได้ เราจำเป็นต้องรู้ว่า SQL Server มีขั้นตอนดำเนินงานกับQueryของเราอย่างไร เพื่อให้เห็นจุดที่เป็นปัญหา คอขวด หรือขั้นตอนที่กินแรง กินทรัพยากรมากผิดปกติ หรือโดยไม่จำเป็น ความรู้ได้เราสามารถหาได้จากการพิจารณาแผนดำเนินการ
เพื่อไม่ให้บทความนี้ยาวเกินไป ผมจะไม่อธิบายวิธีอ่านแผนดำเนินการในทุกแง่มุม แต่จะพูดถึงเฉพาะส่วนที่เกี่ยวกับการเพิ่มประสิทธิภาพQueryในตัวอย่างนี้เท่านั้น หากท่านต้องการอ่านเรื่องแผนดำเนินการโดยละเอียด ให้อ่านได้จากบทความ “การอ่าน Query Execution Plan” ในเว็บไซต์นี้
กดแทป 1 เพื่อเปิดดูแผนการดำเนินการ (Execution Plan)
วิธีอ่านแผนการดำเนินการให้อ่านโดยไล่จากขวาไปซ้าย ล่างขึ้นบน ดังนี้
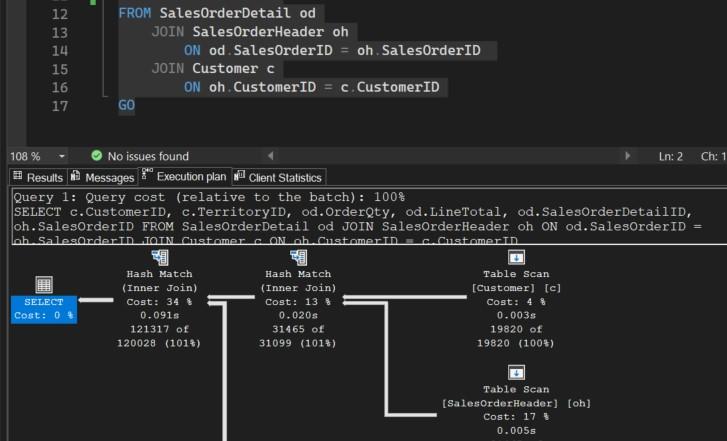
- ไอคอนขวาสุดล่างสุด Table Scan [SalesOrderDetail] [od] มี Cost: 32% นี่เป็นตัวดำเนินการที่ใช้ต้นทุน สูงที่สุด (ต้นทุนหรือ cost คือเวลาที่ใช้ในการทำงาน) สำหรับไอคอนนี้เกิดจากการทำงานของอุปกรณ์บันทึกข้อมูล ทำให้การอ่านข้อมูลทั้งหมดจากตาราง SalesOrderDetail เป็นส่วนสำคัญของต้นทุนรวมของQueryนี้
- 0.034s: เวลาโดยประมาณที่ใช้ในการดำเนินการนี้
- 121317 of 121317 (100%): แสดงว่ามีการสแกนข้อมูลทั้งหมด 121,317 แถวจากตาราง SalesOrderDetail ซึ่งเป็นการสแกนแบบทั้งตาราง (100%)
- ไอคอนขวาสุด กลาง Table Scan [SalesOrderHeader] [oh]
- Cost: 17%: เป็นการดำเนินการที่ใช้ต้นทุนสูงรองลงมา
- 0.005s: เวลาโดยประมาณ
- 31465 of 31465 (100%): เกิดการสแกนข้อมูลทั้งหมด 31,465 แถวจากตาราง SalesOrderHeader
- ไอคอนขวาสุด บนสุด Table Scan [Customer] [c]
- Cost: 4%: เป็นการดำเนินการที่ใช้ต้นทุนต่ำที่สุดในบรรดาการสแกนตาราง
- 0.003s: เวลาโดยประมาณ
- 19820 of 19820 (100%): มีการสแกนข้อมูลทั้งหมด 19,820 แถวจากตาราง Customer
ข้อสังเกตเกี่ยวกับการสแกนตาราง
การที่แผนดำเนินการนี้มีการสแกนตารางแบบเต็ม (100% หรือ Full Table Scan) อยู่สามตำแหน่ง บ่งชี้ว่าQueryนี้ยังไม่มี Index ที่เหมาะสมในคอลัมน์ที่ใช้ WHERE หรือ JOIN การสร้างไฟล์ดรรชนีที่เหมาะสมจะช่วยเพิ่มประสิทธิภาพได้มาก
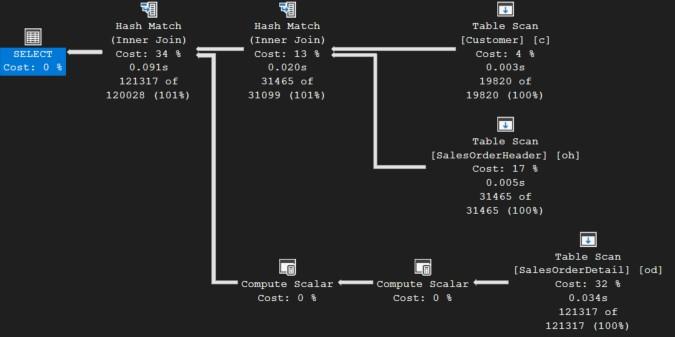
ไอคอน Compute Scalar (การคำนวณค่าสเกลาร์และการแปลงข้อมูล)
ในแผนการดำเนินงานนี้มีไอคอน Compute Scalar สองรายการที่มี Cost: 0% เผยให้เห็นว่าการดำเนินการนี้มีต้นทุนต่ำมาก (แทบจะไม่มี) คำว่า Compute Scalar หมายถึงการคำนวณค่าเดี่ยว (scalar value) จากนิพจน์ต่างๆ เช่น การดึงคอลัมน์ที่ต้องการ หรือการคำนวณทางคณิตศาสตร์เล็กๆ น้อยๆ ในแผนนี้เป็นการประมวลผลข้อมูลจากตาราง SalesOrderDetail เพื่อหาความสัมพันธ์ในการจอยกับตารางอื่น เนื่องจากมีต้นทุนต่ำ สองไอคอนนี้จึงไม่ใช่คอขวดด้านประสิทธิภาพ และต่อไปนี้เราจะไม่สนใจมัน
ไอคอน Hash Match (Inner Join) (การรวมข้อมูล การจอยตาราง)
Hash Match เป็นวิธีหนึ่งในการจอยตารางที่ SQL Server ใช้บ่อย เมื่อตารางที่นำมารวมกันมีขนาดใหญ่และไม่ได้จัดเรียง (sorted) ตามคอลัมน์ที่ใช้จอยหรือเมื่อไม่มีดรรชนีที่เหมาะสมสำหรับการทำลูปซ้อน (Nested Loops)
- Hash Match (Inner Join) ตัวขวา ทำหน้าที่เชื่อมต่อข้อมูลจาก SalesOrderHeader และผลลัพธ์จาก Compute Scalar ของ SalesOrderDetail
- Cost: 13%: มีต้นทุนปานกลาง
- 0.020s: เวลาโดยประมาณ
- 31465 of 31099 (101%): นี่คือการจอยตาราง SalesOrderHeader (มี 31,465 แถว) กับตาราง SalesOrderDetail (ซึ่งมีประมาณ 31,099 แถว) ตัวเลข 101% เป็นค่าประมาณการณ์ที่อาจคลาดเคลื่อนเล็กน้อย แต่โดยพื้นฐานคือมีการนำข้อมูลจากอินพุตทั้งสองมาตรวจหาคู่ที่ตรงกัน การจอยนี้เชื่อมโยงข้อมูลหัวบิลกับรายละเอียดของคำสั่งซื้อ
- Hash Match (Inner Join) ตัวซ้าย เกิดจากการจอบตาราง Customer และผลลัพธ์ของไอคอน Hash Match ก่อนหน้า
- Cost: 34%: เป็นการจอยที่ใช้ต้นทุนสูงที่สุดในแผน
- 0.091s: เวลาที่ใช้โดยประมาณ
- 121317 of 120028 (101%): การจอยนี้เชื่อมต่อตาราง Customer (19,820 แถว) กับผลลัพธ์ของการ จอยก่อนหน้า (120,028 แถว)
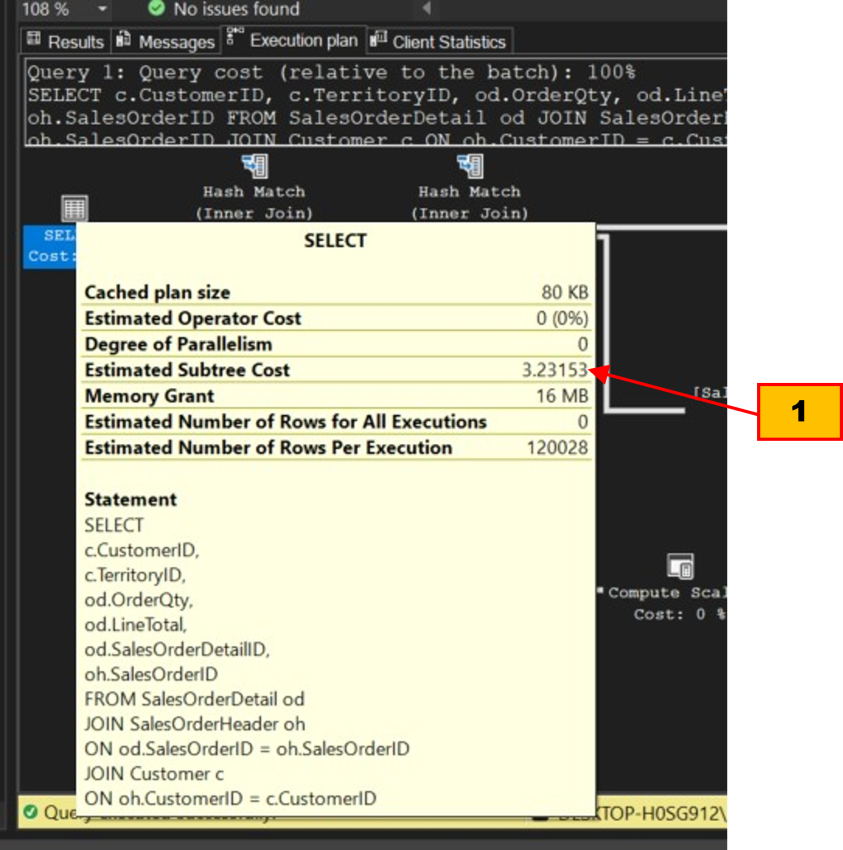
Tool tip ของแผนการดำเนินงาน
เราอาจเรียกดูค่าสรุปประสิทธิภาพการทำงานของQueryได้โดยดูที่ Tool tip ของไอคอนซ้ายสุดในแผนดำเนินงาน ค่าเดียวที่เราให้ความสนใจตอนนี้คือ Estimated Subtree Cost (1) เพราะมันคือค่าสะสมจากการทำงานของทุกไอคอนทางขวารวมเข้าด้วยกัน จะเห็นว่าQueryของเราที่ยังไม่ได้ปรับปรุงใด ๆ มีค่าสะสมอยู่ที่ 3.23153 วินาที ซึ่งถือว่ามีประสิทธิภาพต่ำมาก จำเป็นจะต้องถูกแก้ไขปรับปรุงให้เร็วขึ้น (การเรียกดู Tool tip ของไอคอนใด ๆ ทำได้โดยการคลิกที่ไอคอนนั้น)
ปรับปรุงประสิทธิภาพด้วยการตัดจอยที่ไม่จำเป็น
เมื่อพิจารณาแผนการดำเนินงานโดยรวมแล้ว จะเห็นว่า Hash Match (Inner Join) ตัวซ้าย (ตัวที่เชื่อมต่อข้อมูลจากตาราง Customer) เป็นการจอยที่ใช้ต้นทุนสูงที่สุดในแผน เมื่อรีวิวสคริปต์อย่างถี่ถ้วนท่าน จะพบว่าเราสามารถตัดจอยชุดนี้ออกได้โดยไม่ส่งผลกระทบต่อผลลัพธ์การดำเนินงานของ Query
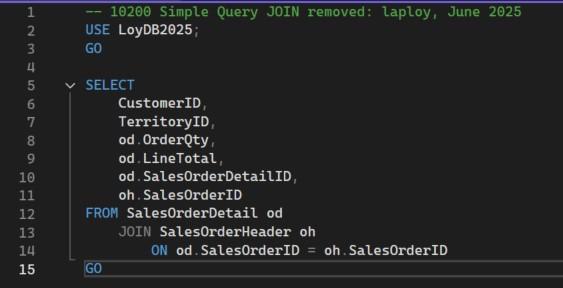
สคริปต์ 10200 Simple Query JOIN removed.sql
เมื่อตัดจอยออกแล้ว จะได้Queryหน้าตาแบบนี้ จะเห็นว่าเรานำคำสั่งส่วนที่เกี่ยวข้องกับตาราง Customer ออกไปทั้งหมด Queryนี้จึงอ้างถึงแค่สองตาราง ได้แก่ตาราง SalesOrderDetail และตาราง SalesOrderHeader เมื่อรันแล้วมีผลให้จำนวนไอคอนภายในแผนดำเนินงานลดลงจาก 8 ตัวเหลือ 6 ตัว
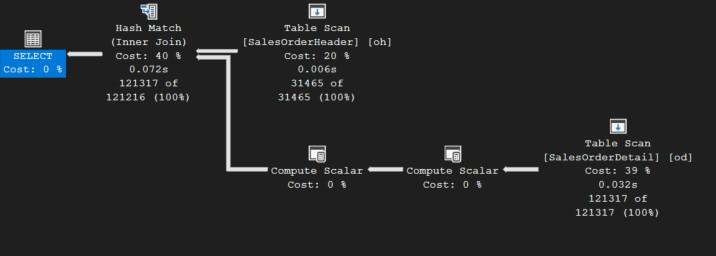
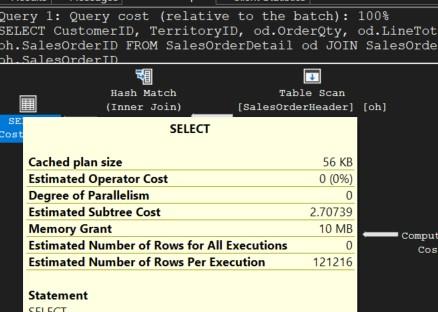
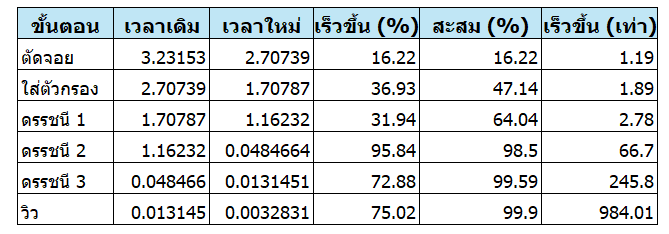
เมื่อดูค่าสรุปที่ Tool tip ของไอคอนซ้ายสุด ท่านจะพบว่า Estimated Subtree Cost ลดลงจาก 3.23153 วินาที เหลือ 2.70739 นั่นคือมีประสิทธิภาพเพิ่มขึ้นร้อยละ 16.22 (16.22%) หรือเร็วกว่าเดิม 1.19 เท่า
ปรับปรุงประสิทธิภาพโดยการใส่ตัวคัดกรอง
ตัวคัดกรองในที่นี้คือคำสั่ง WHERE เพราะถ้าเราดู Tool tip อันล่าสุดตรงบรรทัดสุดท้าย ค่า Estimated Number of Rows Per Execution (จำนวนแถวโดยประมาณ) จะเห็นว่ามีจำนวน 12,1216 แถว ซึ่งทำให้ใช้เวลาทำงานมากโดยไม่จำเป็น เพราะปกติเราจะหาแถวข้อมูลที่จำเพาะเจาะจงเพียงแถวเดียวเท่านั้น ดังนั้นต้องดีแน่ถ้าเราใส่เงื่อนไขการคัดกรองข้อมูลให้เหลือแค่แถวเดียว โดยใช้คำสั่งนี้
WHERE od.SalesOrderDetailID = 61037 AND oh.territoryID = 7
(เอาแถวข้อมูลเฉพาะคำสั่งซื้อ 61037 ของพื้นที่การขาย 7)
Query ที่ได้จะมีหน้าตาดังนี้
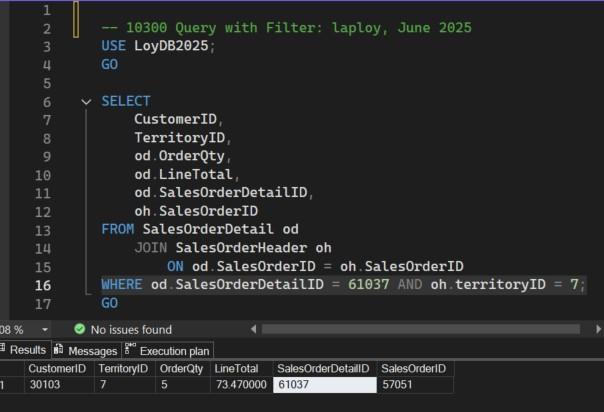
สคริปต์ 10300 Query with Filter.sql
เมื่อQueryทำงานเสร็จให้ดู Tool tip ของไอคอนซ้ายสุด จะเห็นว่า Estimated Subtree Cost ลดลงจาก 2.70739 เหลือ 1.70787 วินาที นั่นคือมีประสิทธิภาพเพิ่มขึ้นร้อยละ 36.93 (36.93%) จากขั้นตอนก่อนหน้า หรือ 47.14% จากตอนที่ยังไม่ได้ทำออพติไมซ์ หรือพูดอีกอย่างหนึ่งคือเร็วกว่าตอนที่ยังไม่ได้ทำออพติไมซ์ 1.89 เท่า

ปรับปรุงประสิทธิภาพด้วยการสร้างดรรชนี IX_SalesOrderHeader_TerritoryID
แค่นี้ยังเร็วไม่พอ เรายังต้องการปรับปรุงประสิทธิภาพของQueryให้ดีขึ้นอีก มาพิจารณาแผนดำเนินงานอันล่าสุดกันอีกครั้ง จะพบว่าไอคอนตัวที่วงไว้มีการทำงานแบบ Table Scan ซึ่งช้า (ที่เร็วกว่าคือการทำงานแบบ index seek) เผยให้เห็นว่าตารางนี้ยังไม่มีดรรชนีที่เหมาะสม
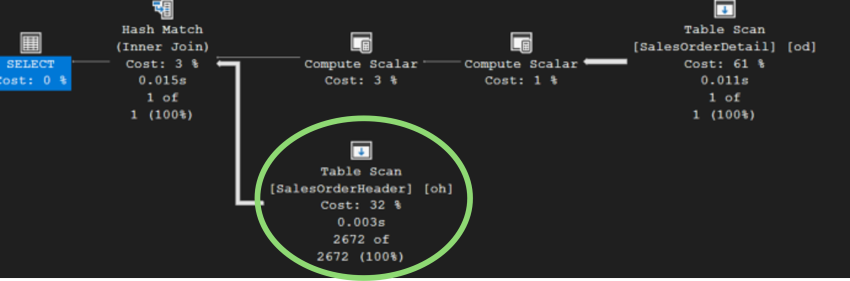
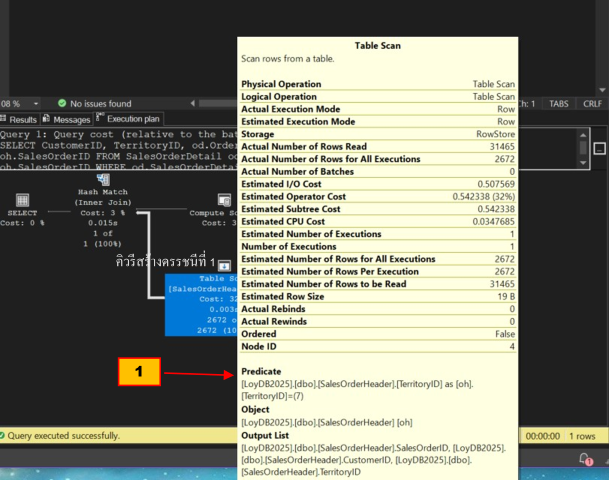
กดที่ไอคอนนี้เพื่อดู Tool Tip ดูหัวข้อ Predicate (1) ที่บอกเป็นนัยว่าคอลัมน์ที่ยังขาดดรรชนีคือ TerritoryID ของตาราง SalesOrderHeader
เราจำเป็นต้องสร้างดรรชนีให้ตาราง SalesOrderHeader ซึ่งสร้างได้สองแบบคือ Clustered และ Nonclustered เชื่อว่าท่านน่าจะรู้จักความแตกต่างระหว่างดรรชนีทั้งสองแบบดีอยู่แล้ว แต่ถ้าท่านเลือน ๆ ไป ผมขอทบทวนความจำอย่างย่อด้วยตารางนี้

แม้ดรรชนีแบบเร็วที่สุดคือ Clustered แต่เราจะสร้างแบบ Nonclustered เพราะค่าในคอลัมน์ TerritoryID ไม่เหมาะทำดรรชนีแบบ Clustered สคริปต์สำหรับสร้างดรรชนีเป็นดังนี้
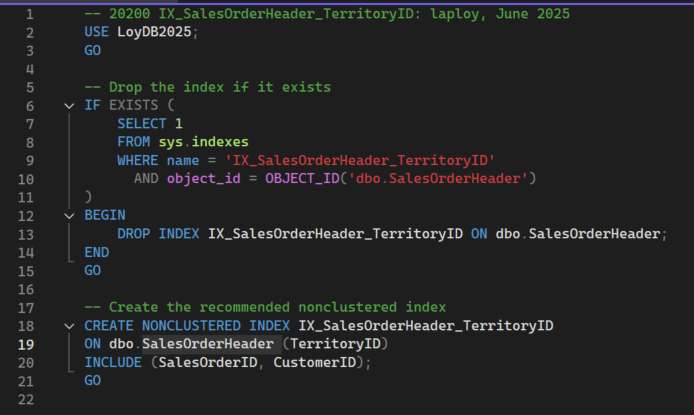
สคริปต์ 20200 IX_SalesOrderHeader_TerritoryID.sql
คำอธิบายสคริปต์
- บรรทัดที่ 6-14: ทำหน้าที่ตรวจสอบว่ามี Index ชื่อ IX_SalesOrderHeader_TerritoryID อยู่บนตาราง SalesOrderHeader แล้วหรือไม่ ถ้ามีจะลบดัชนีนั้นออก เพื่อเตรียมสร้างใหม่ การใส่โค้ดนี้อำนวยความสะดวกในการทดสอบและป้องกันเออเรอร์
- บรรทัดที่ 18-20: สร้างดรรชนี Nonclustered ใหม่บนคอลัมน์
TerritoryIDใช้คำสั่ง
INCLUDEเพิ่มคอลัมน์
SalesOrderIDและ
CustomerIDเข้าไปด้วย เพื่อให้Queryดึงข้อมูลจากคอลัมน์เหล่านี้ทำงานได้เร็วขึ้น โดยไม่ต้องเข้าถึงแถวข้อมูลจริง
เมื่อท่านรันสคริปต์นี้แล้วให้รันสคริปต์ 10300 Query with Filter.sql เพื่อดูผลลัพธ์การทำงาน จะเห็นว่าประสิทธิภาพของการทำงานดีขึ้น ดูได้จากไอคอนตัวล่างสุดที่เดิมเป็น Table Scan ตอนนี้เปลี่ยนเป็น Index Seek และ Cost ลดลงเป็น 1% (จากเดิม 32%)
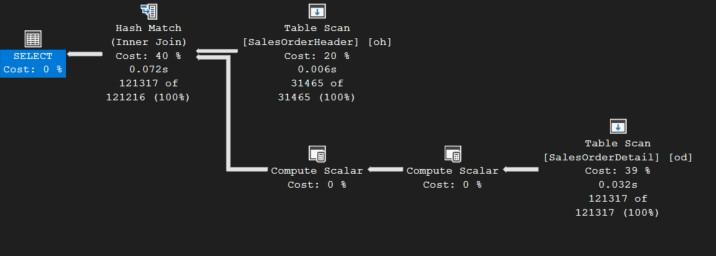
ตรวจดูที่ Tool tip ของไอคอนซ้ายสุดจะเห็นภาพนี้

จะเห็นว่า Estimated Subtree Cost ลดลงจาก 1.70787 เหลือ 1.16232 วินาที นั่นคือมีประสิทธิภาพเพิ่มขึ้นร้อยละ 31.94 (31.94%) จากขั้นตอนก่อนหน้า หรือ 64.04% จากตอนที่ยังไม่ได้ทำดรรชนี หรือพูดอีกอย่างหนึ่งคือเร็วกว่า ตอนที่ยังไม่ได้ทำออพติไมซ์ 2.78 เท่า
ปรับปรุงประสิทธิภาพด้วยดรรชนี IX_SalesOrderDetail_SalesOrderDetailID
แม้ว่าการทำงานจะมีประสิทธิภาพเพิ่มขึ้น 64.04% แล้ว แต่เรายังไม่พอใจ เรายังต้องการปรับปรุงประสิทธิภาพของQueryขึ้นไปอีก พิจารณาแผนดำเนินงานอันล่าสุดอีกครั้ง จะพบว่าไอคอนตัวที่ขวาสุดยังมีการทำงานแบบ Table Scan ซึ่งไม่ดี เมื่อดูที่หัวข้อพรีดิเคทใน Tool Tip จะพบว่าปัญหาอยู่ที่ ตาราง SalesOrderDetail คอลัมน์ SalesOrderDetailID ยังขาดดรรชนี ดังนั้นเราจะสร้างดรรชนีชื่อ IX_SalesOrderDetail_SalesOrderDetailID ซึ่งมีโค้ดดังนี้
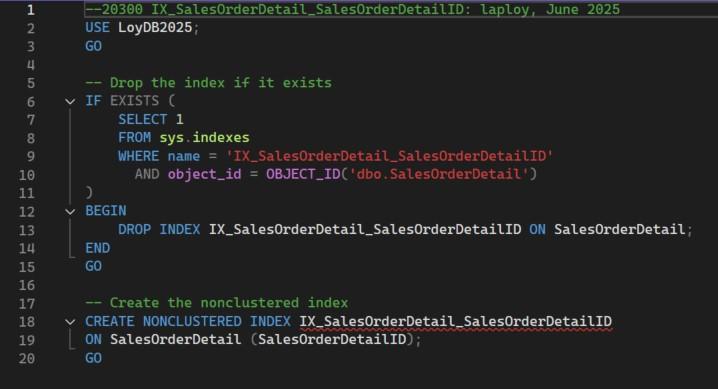
สคริปต์ 20300 IX_SalesOrderDetail_SalesOrderDetailID.sql
คงไม่ต้องอธิบายสคริปต์นี้แล้ว เพราะไม่ต่างจากสคริปต์ก่อนหน้ามากนัก แค่เปลี่ยนเป็นตาราง SalesOrderDetail คอลัมน์ SalesOrderDetailID เท่านั้น
รันสคริปต์นี้แล้วรันสคริปต์ 10300 Query with Filter.sql เพื่อดูผลลัพธ์การทำงานอีกครั้ง ท่านจะเห็นว่าประสิทธิภาพของการทำงานดีขึ้น ไอคอนตัวที่วงไว้ เดิมเป็น Table Scan ตอนนี้เปลี่ยนเป็น Index Seek และ Cost ลดลงเป็น 7% (จากเดิม 90%)
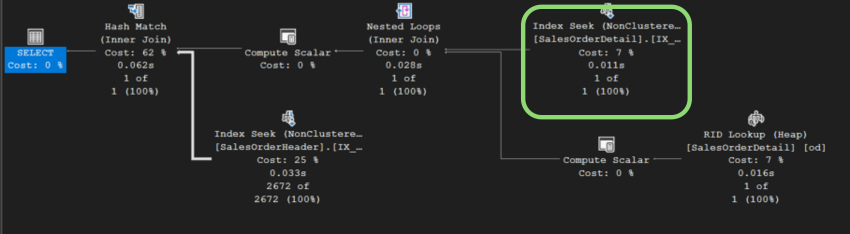
ดูที่ Tool tip ของไอคอนซ้ายสุด

จะเห็นว่า Estimated Subtree Cost ลดลงจาก 1.16232 วินาที เหลือ 0.0484664 นั่นคือมีประสิทธิภาพเพิ่มขึ้นร้อยละ 95.84 (95.84%) จากขั้นตอนก่อนหน้า หรือ 98.5% จากตอนที่ยังไม่ได้ออพติไมซ์ หรือพูดอีกอย่างหนึ่งคือเร็วกว่า ตอนที่ยังไม่ได้ทำออพติไมซ์ 66.7 เท่า
ปรับปรุงประสิทธิภาพด้วยการใส่ดรรชนี IX_SalesOrderHeader_SalesOrderID
ตอนนี้การทำงานมีประสิทธิภาพเพิ่มขึ้น 98.5% แต่เรายังไม่พอใจอยู่ดี โปรดพิจารณาแผนดำเนินงานอันล่าสุดอีกครั้ง จะพบว่าไอคอนตัวที่วงไว้ แม้จะเป็น index seek แล้ว แต่ยังมี Cost ในการทำงานมากถึง 25% เมื่อตรวจดูที่พรีดิเคทของ Tool Tip (ของไอคอนนี้) จะพบว่าปัญหาอยู่ที่ ตาราง SalesOrderHeader คอลัมน์ SalesOrderID ที่ยังขาดดรรชนีอยู่
ดังนั้นเราจะสร้างดรรชนีชื่อ IX_SalesOrderHeader_SalesOrderID เพื่อทำหน้าที่เป็น cover index ด้วยโค้ดดังนี้
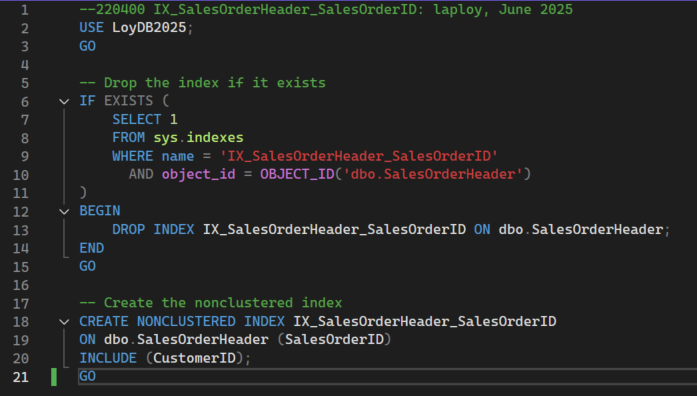
สคริปต์ 20400 IX_SalesOrderHeader_SalesOrderID.sql
รันสคริปต์นี้แล้วรันสคริปต์ 10300 Query with Filter.sql เพื่อดูผลลัพธ์การทำงาน จะเห็นว่าประสิทธิภาพดีขึ้น ดูที่ Tool tip ของไอคอนซ้ายสุดมีค่า Estimated Subtree Cost ลดลงจาก 0.0484664 วินาที เหลือ 0.0131451 นั่นคือมีประสิทธิภาพเพิ่มขึ้นร้อยละ 72.88 (72.88%) จากขั้นตอนก่อนหน้า หรือ 99.59% จากตอนที่ยังไม่ได้สร้างดรรชนีนี้ หรือพูดอีกอย่างหนึ่งคือเร็วกว่า ตอนที่ยังไม่ได้ทำออพติไมซ์ 245.8 เท่า

ปรับปรุงประสิทธิภาพด้วย View
ตั้งแต่ต้นจนถึงตอนนี้ เราออพติไมซ์ด้วยการปรับปรุงตัวQueryและสร้างไฟล์ดรรชนีสามไฟล์ ผลลัพธ์คือการทำงานมีประสิทธิภาพสูงขึ้นร้อยละ 99.59 ลดเวลาทำงานลงจาก 3.23153 วินาที เหลือ 13.1451 มิลลิวินาที สำหรับการใช้งานทั่วไปนี่ถือว่าดีมากแล้ว แต่สำหรับการใช้งานความถี่สูง (เช่นเว็บแอพหรือโมบายล์แอพ ที่มีผู้ใช้จำนวนมากจากทั่วโลก เรียกใช้ฟังก์ชันที่เกี่ยวข้องกับQueryนี้) แค่นี้อาจยังเร็วไม่พอ ดังนั้นในหัวข้อนี้จะนำเสนอการออพติไมซ์โดยใช้วิว
View คืออะไร?
View คือตารางเสมือนที่สร้างจากคำสั่ง SELECT ไม่เก็บข้อมูลไว้ในฐานข้อมูล แต่ทุกครั้งที่เราเรียก view เซิร์ฟเวอร์จะไปดึงข้อมูลจากตารางต้นฉบับตามQueryในวิว ๆ มีไว้ใช้เพื่อทำให้โค้ดอ่านง่ายขึ้น ช่วยควบคุมการเข้าถึงข้อมูล เราสามารถเรียกใช้วิวโดยตรง หรือจะอ้างถึงในQueryเหมือนกับว่ามันเป็นตารางข้อมูลก็ได้
ต่อไปนี้เราจะสร้างวิวชื่อ vSalesOrderDetail ที่มีคำสั่ง SELECT เหมือนในสคริปต์ 10300 Query with Filter.sql ทุกประการ และจะสร้างดรรชนีให้มันด้วย Queryสำหรับสร้างวิวนี้เป็นดังนี้
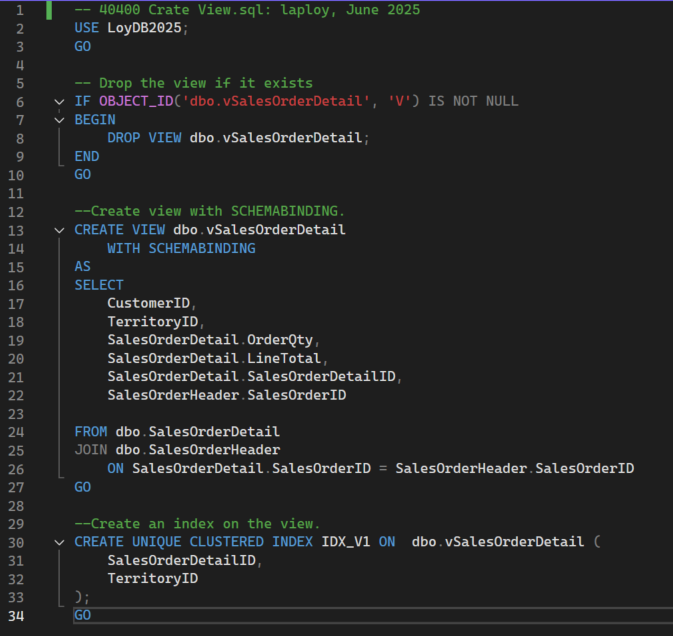
40400 Crate View.sql
คำอธิบายสคริปต์
- บรรทัดที่ 6-9: ตรวจสอบว่ามีวิวนี้อยู่ในฐานข้อมูลแล้วหรือยัง ถ้ามีให้ลบ
- บรรทัดที่ 13: กำหนดชื่อวิว
- บรรทัดที่ 14: คำสั่ง SCHEMABINDING เป็นเงื่อนไขจำเป็นหากต้องการสร้างดรรชนีบน view
- บรรทัดที่ 16-27: เป็นQueryที่เหมือนกับสคริปต์ 10300 Query with Filter.sql ทุกประการ
- บรรทัดที่ 30-33: สร้างดรรชนี clustered แบบ unique ที่จะทำให้ view นี้มีประสิทธิภาพสูงขึ้น เพราะSQL Server จะเก็บผลลัพธ์ของวิวไว้รอใช้งาน (เทียบได้กับวิวแบบ materialized view ใน Oracle หรือ PostgreSQL) ที่ช่วยให้การดึงข้อมูลทำได้อย่างรวดเร็ว
Queryสำหรับการเรียกข้อมูลผ่านวิว
เมื่อสร้างวิวแล้ว เราสามารถQueryวิวได้เหมือนกับตาราง ๆ หนึ่ง โปรดสังเกตคำสั่ง WITH (NOEXPAND) ซึ่งทำหน้าที่บังคับให้ SQL Server ใช้งานดรรชนีที่เราสร้างไว้ในวิวนี้ (ที่ต้องใส่คำสั่งนี้เพราะทดสอบด้วย SQL Server Express ที่จะไม่เรียกใช้ดรรชนีของวิวโดยอัตโนมัติ หากท่านใช้ edition อื่น เช่น Standard, Enterprise และ Web ให้ลบคำสั่งนี้ออก)
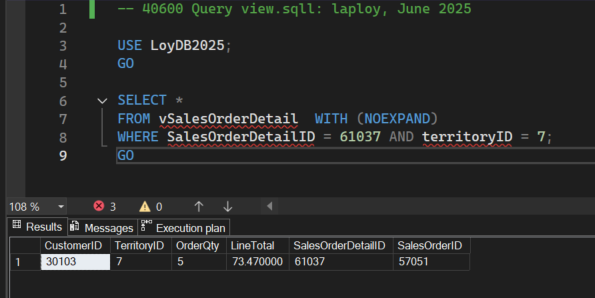
40600 Query view.sql
การสร้างดรรชนีให้ View ช่วยเพิ่มประสิทธิภาพได้อย่างไร?
โดยปกติ View จะประมวลผลใหม่ทุกครั้งที่ถูกเรียกใช้ แต่เมื่อมันมีดรรชนีแล้ว SQL Server จะจัดเก็บผลลัพธ์บางส่วนไว้ล่วงหน้า เพื่อให้สามารถใช้ดรรชนีค้นหาข้อมูลในวิวได้อย่างรวดเร็วเหมือนใช้ดรรชนีบนตารางจริง เมื่อตัวปรับปรุงQuery (Query Optimizer เป็นโปรแกรมภายใน SQL Server) พบว่าวิวมีดรรชนี มันจะใช้วิวแทนการจอยตารางต้นทางทั้งหมด ซึ่งช่วยเพิ่มประสิทธิภาพได้อย่างมาก
การสร้างดรรชนีให้แก่วิวจึงเปรียบเสมือนการ “เตรียมสำรับข้อมูลไว้ล่วงหน้า” ช่วยให้ SQL Server สามารถหยิบใช้ได้เร็วขึ้นโดยไม่ต้องประมวลผลใหม่ทุกครั้ง
แผนดำเนินงานขั้นสุดท้าย
เมื่อดูที่แผนดำเนินงานล่าสุดจะพบว่าการออพติไมซ์มาถึงจุดที่เข้มข้นในระดับสูงสุด เพราะเหลือไอคอนเพียงสองตัว ตัวขวาเป็น index seek กับดรรชนี IDX_V1 ตามที่เราต้องการ ส่วนตัวซ้ายเป็นแค่ตัวแสดงการทำงานไม่มี cost ใด ๆ
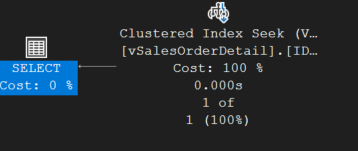
ดูที่ Tool tip ของไอคอนซ้ายสุด จะพบว่า Estimated Subtree Cost ลดลงจากขั้นตอนก่อนหน้า 0.0131451 วินาที เหลือ 0.0032831 นั่นคือมีประสิทธิภาพเพิ่มขึ้นร้อยละ 75.02 (75.02%) จากขั้นตอนก่อนหน้า หรือ 99.9% จากตอนที่ยังไม่ได้ออพติไมซ์ หรือพูดอีกอย่างหนึ่งคือเร็วกว่า ตอนที่ยังไม่ได้ทำ Optimize 984 เท่า

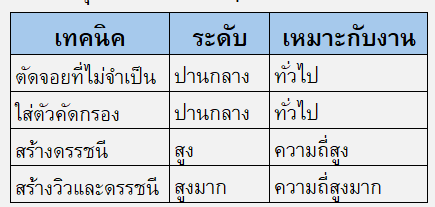
ตารางสรุปประสิทธิภาพจากแต่ละขั้นตอนการ Optimize
สรุป
ทความนี้แสดงวิธีปรับปรุงประสิทธิภาพการทำงานของ Query เพื่อให้แอพทำงานได้รวดเร็วราบรื่นขึ้น เทคนิคที่ใช้มีหลายอย่าง เช่น การตัดจอยที่ไม่จำเป็น การใส่คำสั่ง WHERE เพื่อคัดกรองข้อมูล การสร้างดรรชนีครอบคลุม (cover index) และการสร้างวิวแบบมีดรรชนีเป็นต้น
ตารางสรุปว่าเทคนิคต่าง ๆ สามารถช่วยได้ในระดับใดและเหมาะกับงานใด